Intro to EAM
@47th ECVP 2025 Mainz
August 24, 2025
Why should we use Evidence Accumulation Models?
accuracy
RT
Can we put them together?

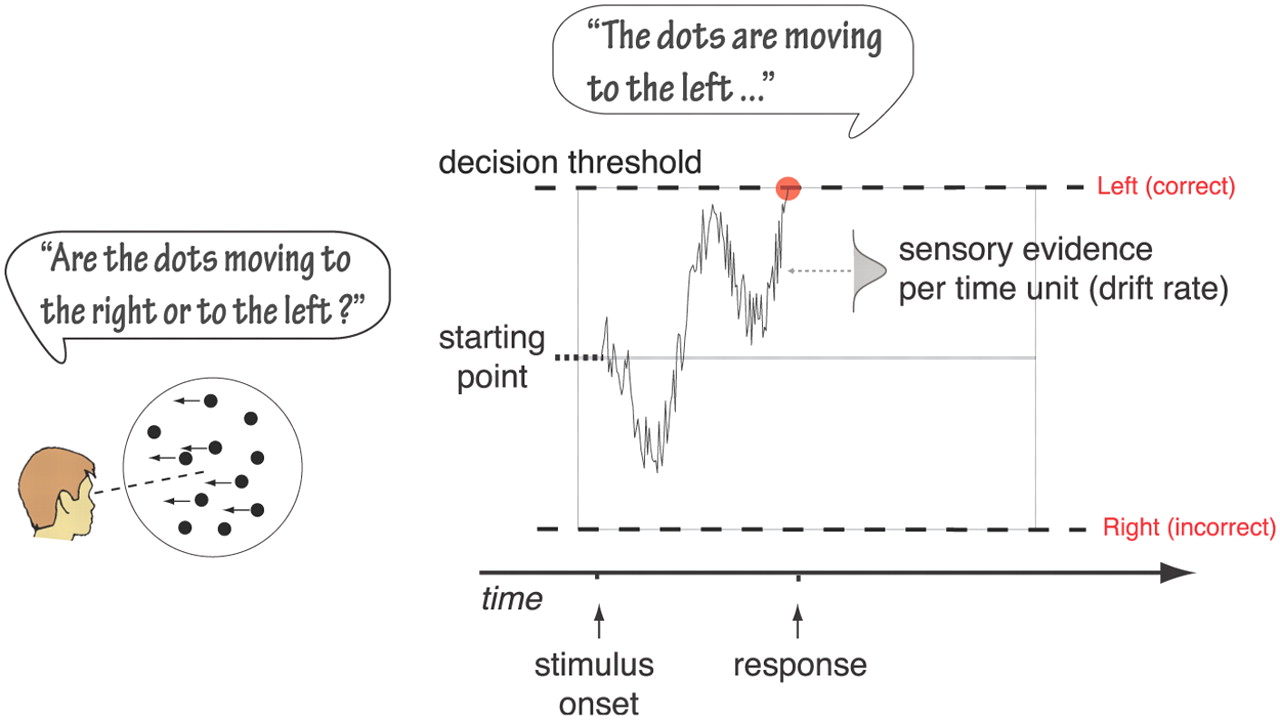
Evidence Accumulation Models
Evidence Accumulation Models assume that, upon stimulus presentation, the decision maker:
- Samples noisy evidence for available options (e.g., “Should I press left or right?”)
- Accumulates that evidence until a threshold is crossed
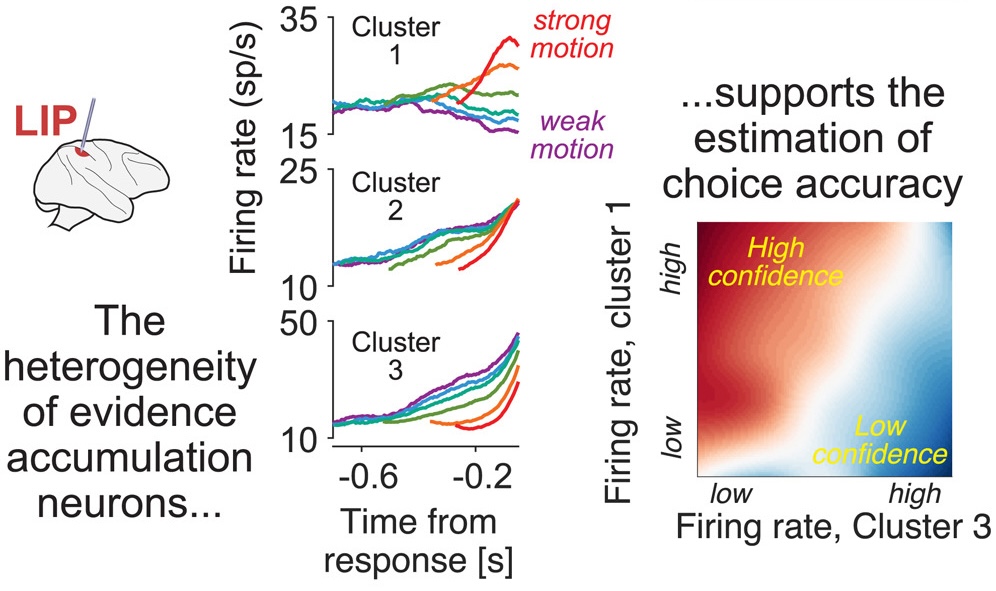
Integrator neurons receive this input
Neurons in LIP, dlPFC, or striatum ramp up/down over time.
Reflects accumulated evidence
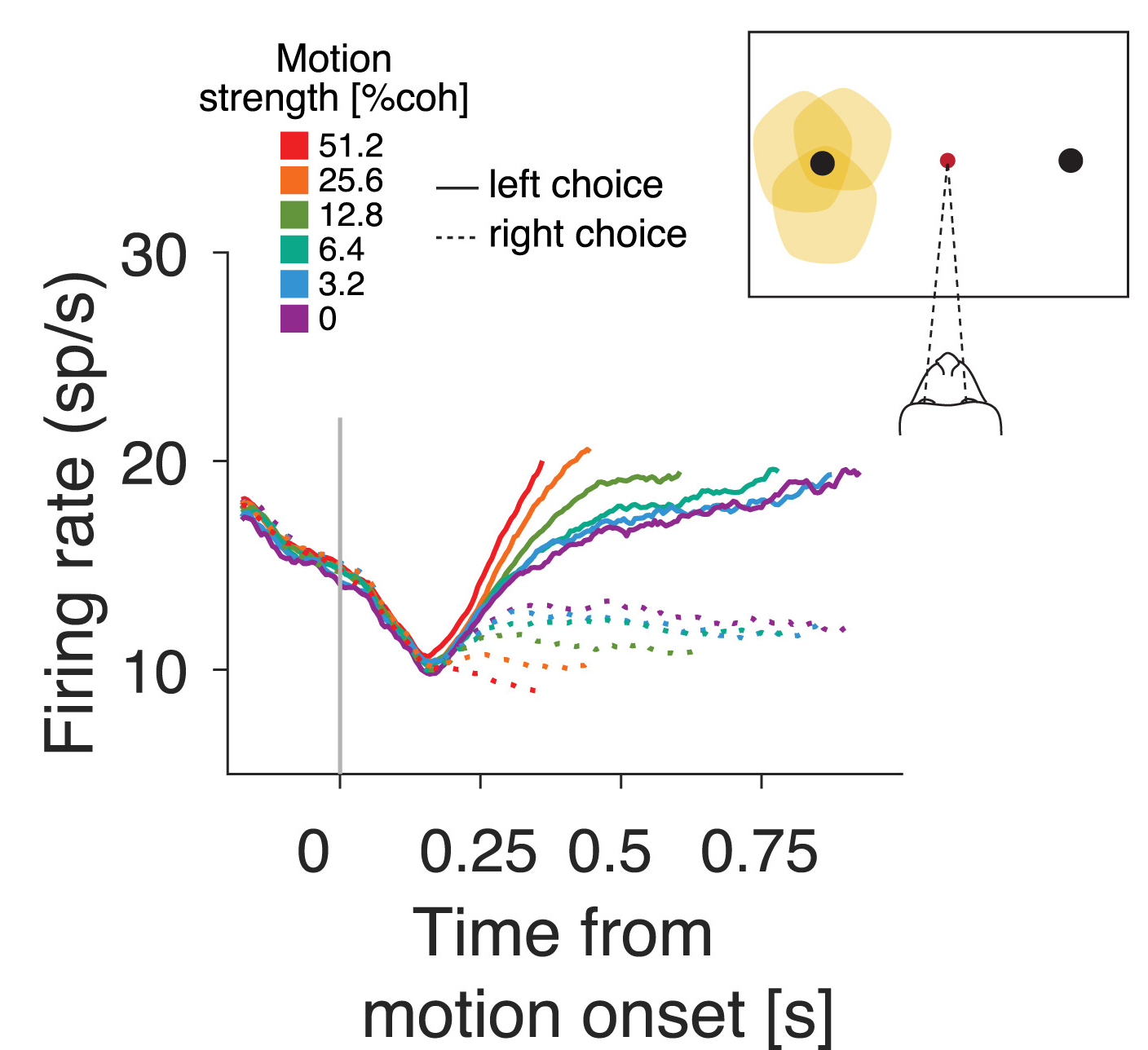
Threshold crossing triggers a decision
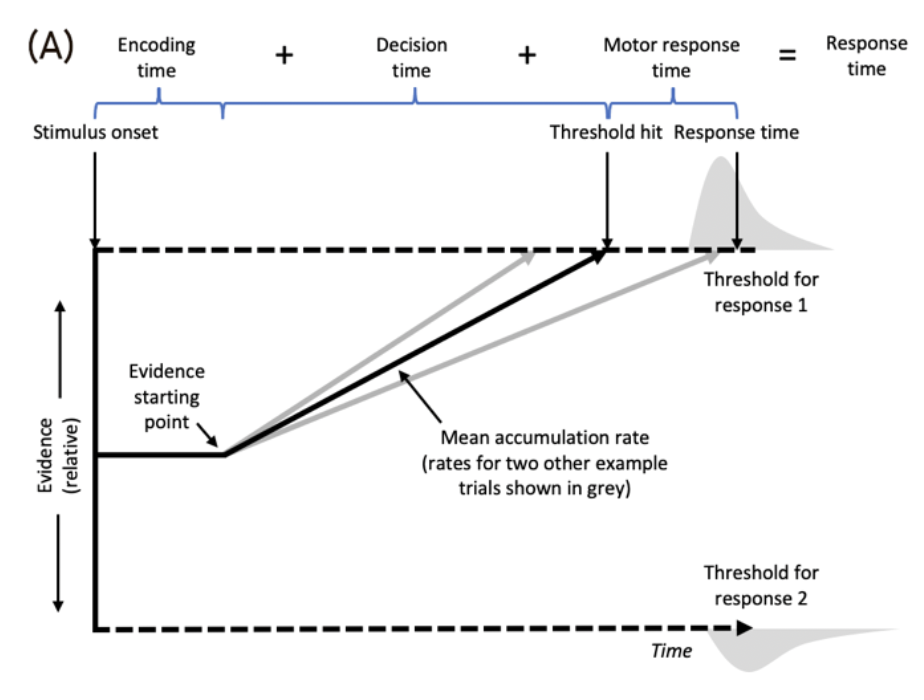
Relative Evidence Models
In relative evidence models (e.g., Wiener process, Diffusion Decision Model):
- Decision is based on the difference in accumulated evidence between two options.
- Suitable for binary choices.
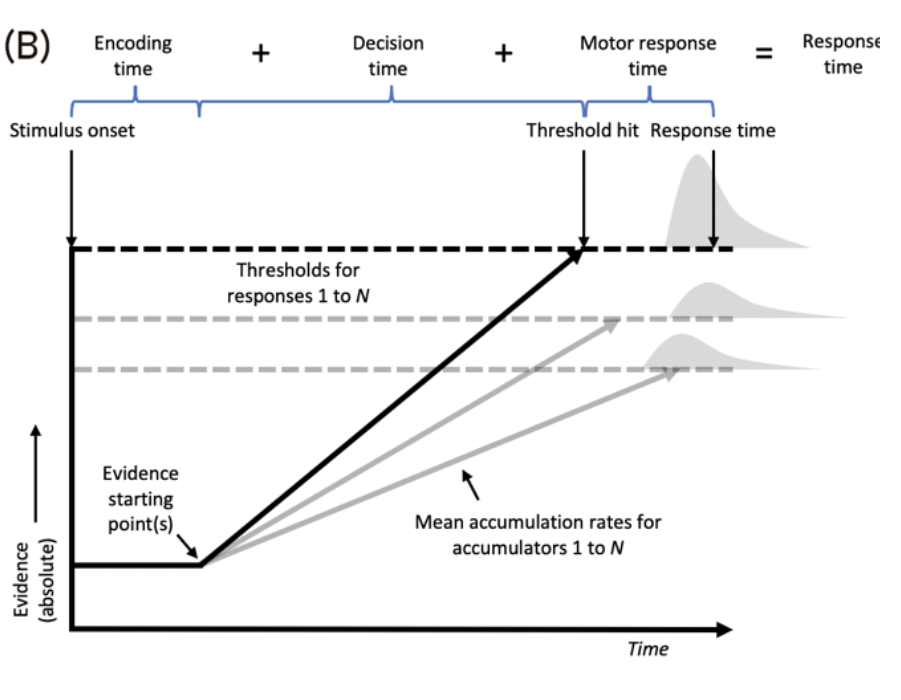
Absolute Evidence Models
In racing accumulator models (e.g., LBA, LNR, RDM):
Each option has its own accumulator tracking absolute evidence.
Decision is made by the first accumulator to reach threshold.
Can handle multiple alternatives (not just binary choices).
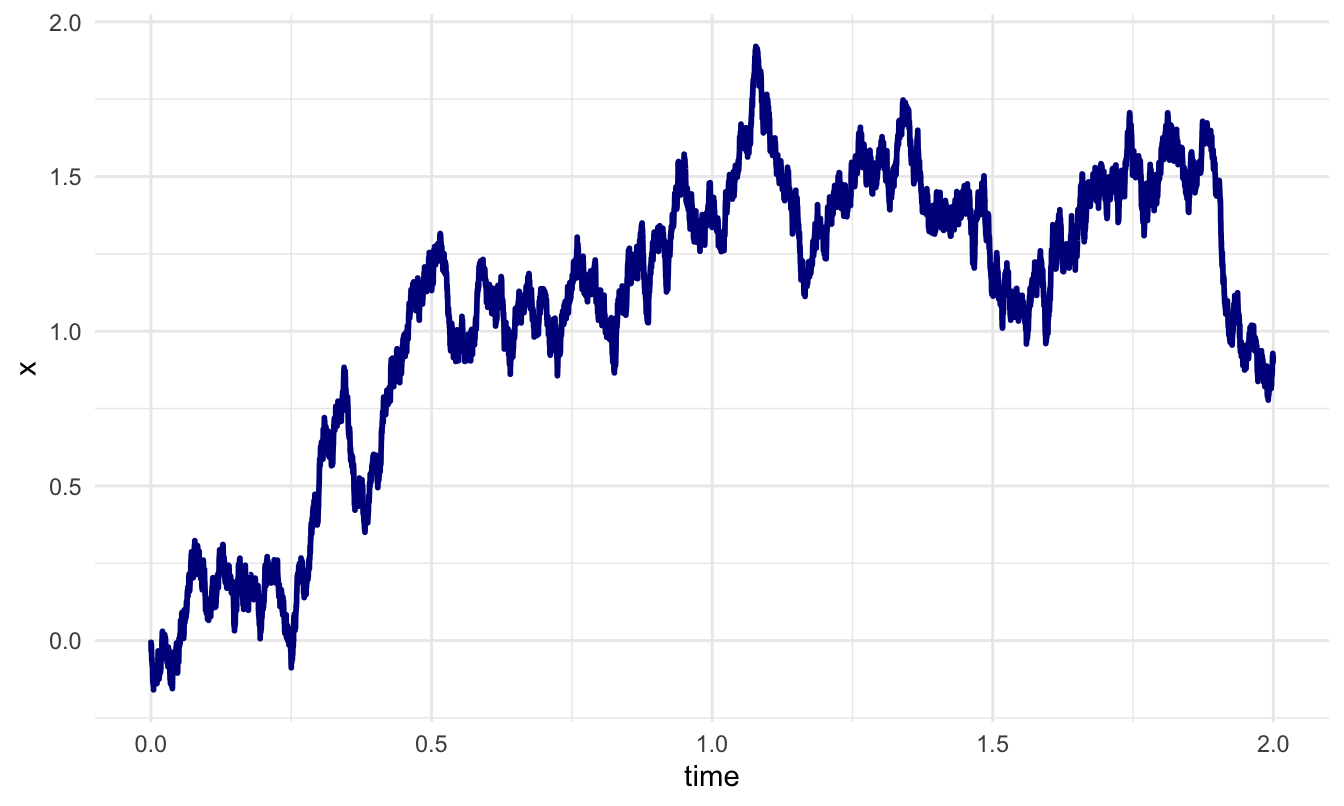
Wiener Diffusion Model
It is the expected distribution of the time until the process first hits or crosses one or the other boundary. This results in a bivariate distribution, over responses and hitting times.
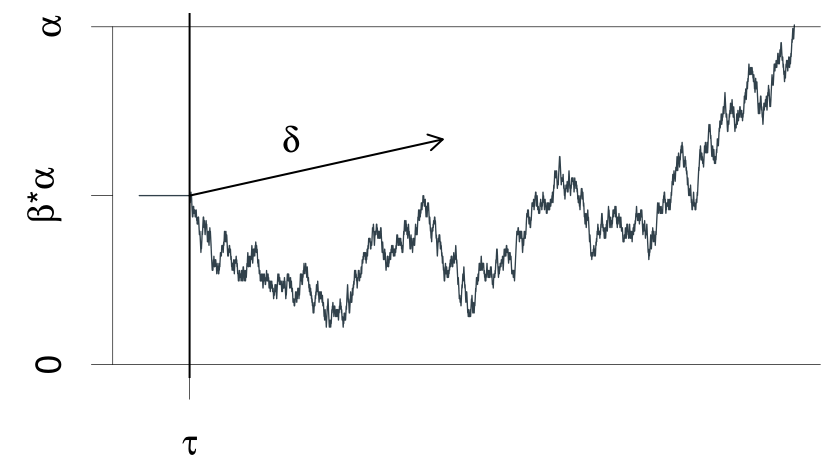
- : threshold
- : initial bias (starting point)
- : quality of the stimulus (often )
- : non-decision time
Navarro & Fuss, 2009; Wabersich & Vandekerckhov, 2014. Copyright 2009, Joachim Vandekerckhove and Department of Psychology and Educational Sciences, University of Leuven, Belgium
Full DDM Parameters
: decision boundary
: starting point
: drift rate
: non-decision time
: noise scale (usually fixed to 1)
: variability in drift rate
: variability in start point
: variability in non-decision time
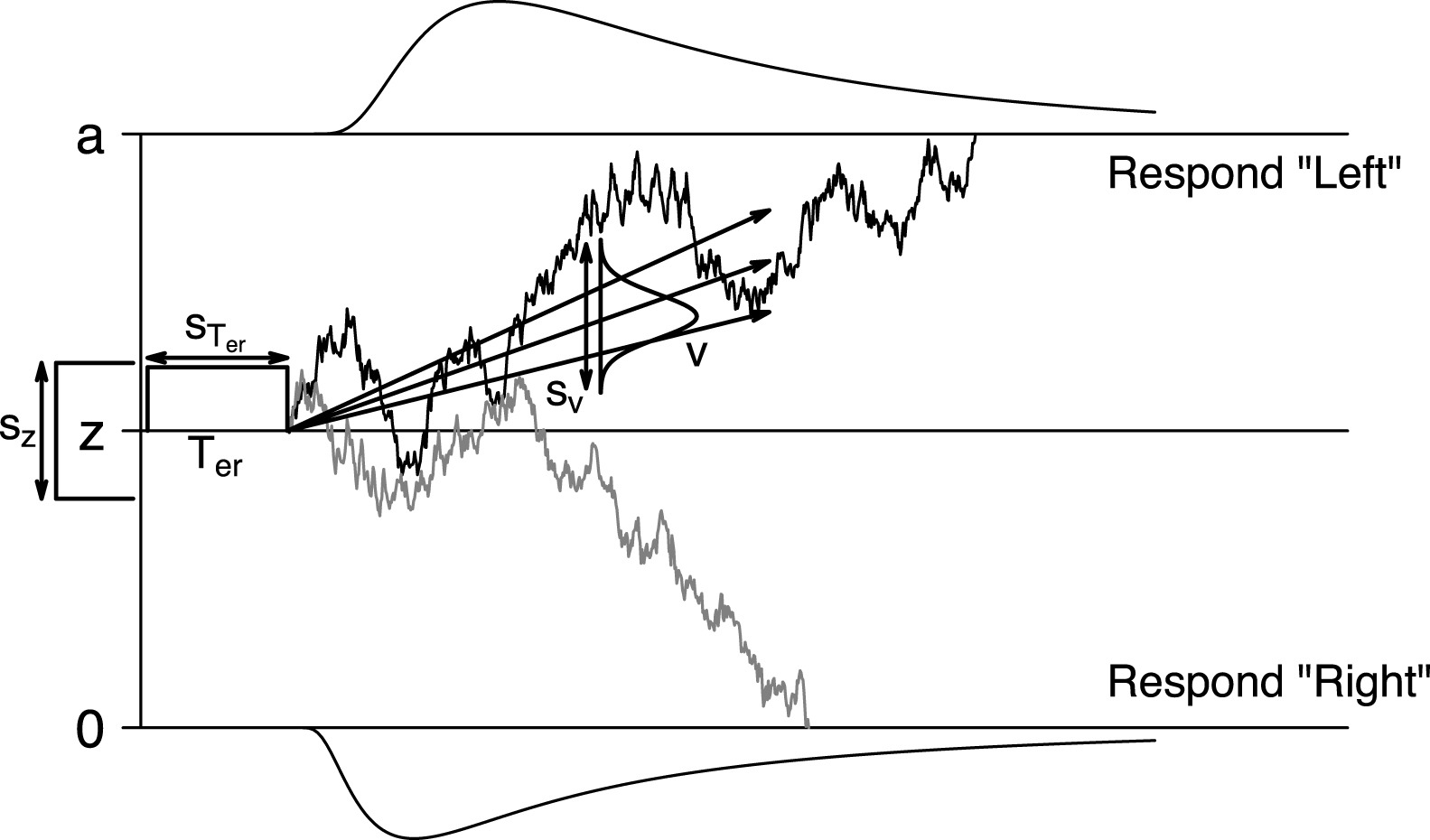
Boehm, U., Annis, J., Frank, … & Wagenmakers, E. J. (2018). Estimating across-trial variability parameters of the Diffusion Decision Model: Expert advice and recommendations. Journal of Mathematical Psychology, 87, 46-75. Ratcliff, R., & Rouder, J. N. (1998). Modeling Response Times for Two-Choice Decisions. Psychological Science, 9(5), 347-356.
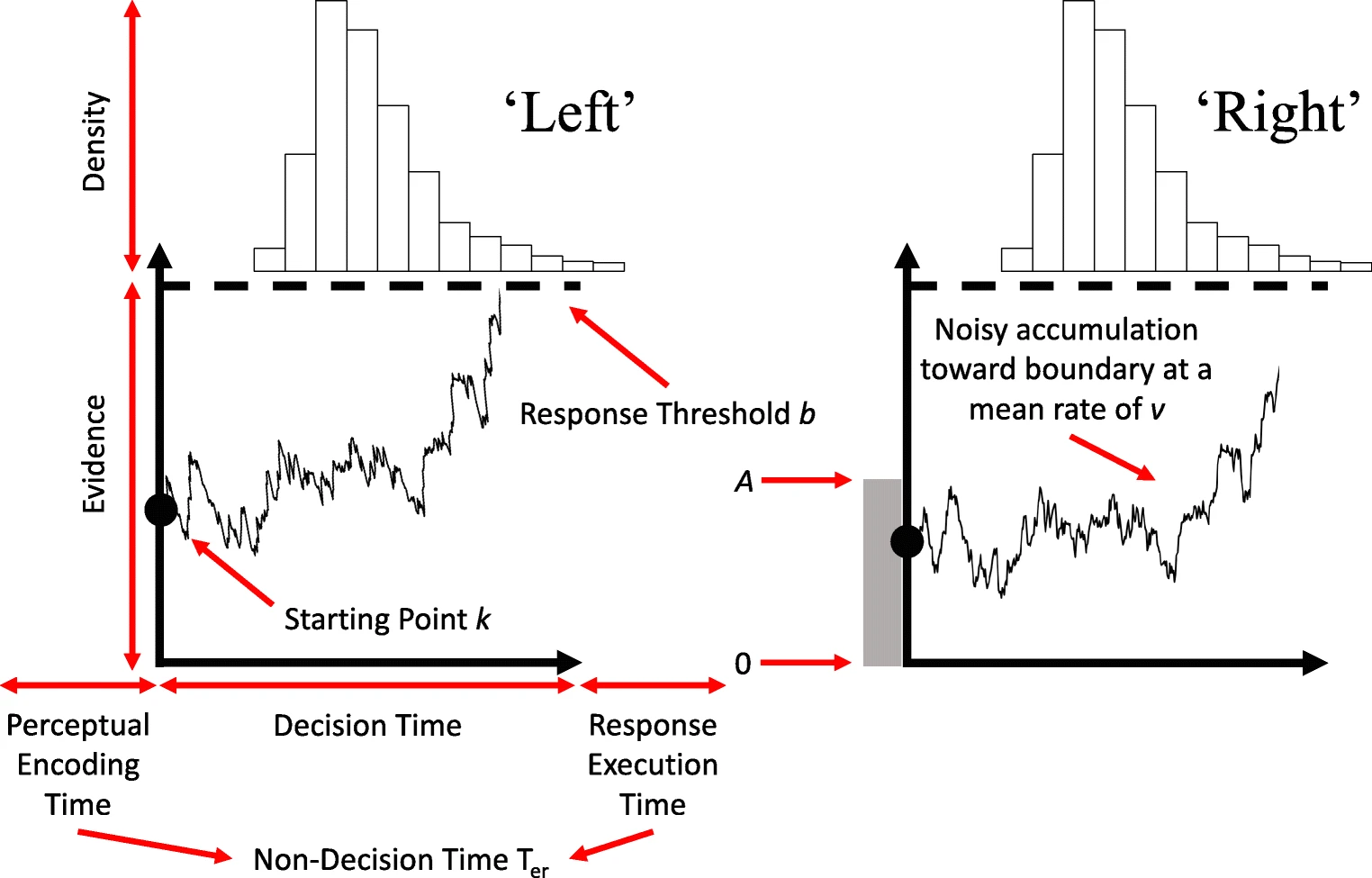
Racing Diffusion Model
Instead of a single process choosing between boundaries, the RDM uses multiple independent diffusion processes, one per option. Each accumulator races toward its threshold. The first to cross wins. Tillman, Van Zandt, & Logan, 2020
Pratical Example (by Carolina Maria Oletto)

Task: targets (peripheral) lines orientation judgement left vs right.




Let’s do it!
![]()